
Three reasons to optimize the edge with distributed disaggregation
As technology continuously innovates to produce exponential improvements in processing and storage performance to keep pace with the demands of the digital world, new computing architectures must be considered. With edge environments’ constrictions on power, footprint and latency, disaggregating compute resources is becoming the new architecture for edge processing. The following are three reasons why system integrators are adapting to this revolutionary way of processing mission-critical data for real-time decision-making:
1) Decreased Thermal Design Power (TDP) through GPU Utilization
To maintain state-of-the-art computing capabilities on a given platform, the default tech refresh approach is to re-specify new server configurations with the latest x86 server-class CPU processors. Each new processing refresh, however, creates an increasing thermal challenge with thermal design power (TDP) ratings doubling over the last four generational refreshes.
To optimize architectures, certain computing tasks are assigned to traditional CPUs with other hardware, such as graphics processing units (GPUs), given math-intensive duties where parallel processing is well suited to handle data streams from multiple sensor sources through various types of algorithms, such as deep learning/machine learning neural networks for artificial intelligence (AI). In AI inference benchmark tests performed by NVIDIA, an A100 GPU outperformed a CPU by 249x. By offloading tasks such as inferencing and training to GPUs, there is no longer a need to over-specify CPUs, which presents an opportunity to decrease TDP.
Even more significant, by distributing across the network, a greater portion of the resource can be used. Instead of specifying GPUs into each system and using a percentage of each GPU, fewer GPUs can be used and distributed to a greater number of systems, mitigating the trend in thermal increase.
2) Low-Latency, Network-Attached Everything, and Shared GPU Resources
The rugged data center at the edge can immediately benefit from disaggregation by embracing hardware such as Data processing units (DPUs). For instance, NVIDIA’s Bluefield shown in Figure 1, are sometimes described as smart networking interface cards (NICs), with additional integrated functionality including CPU processing cores, high-speed packet processing, memory, and high-speed connectivity (e.g., 100 Gbps/200 Gbps Ethernet). Working together, these elements allow a DPU to perform the multiple functions of a network data path acceleration engine. One function very important to edge applications is the ability to feed networked data directly to GPUs using direct memory access (DMA) without any involvement by a system CPU. More than just a smart NIC, DPUs can be used as standalone embedded processors that incorporate a PCIe switch architecture to operate as either root or endpoints for GPUs, NVMe storage and other PCIe devices. This enables a shift in system architectures: rather than specifying a certain predetermined mix of GPU-equipped and general-compute servers, the DPU now enables the GPU resources to be shared at low-latency speeds, wherever most required.
DPU use cases are not limited to GPUs and parallel processing. For instance, the GPU card could instead be a pool of drives, networked and appearing as local storage to any system. Making resources available directly to the network, whether it is parallel processing or storage, allows future scalability and refresh to newer, more capable hardware without a complete overhaul of existing systems or compromising on power budget or low latency.

Figure 1. NVIDIA Bluefield DPU card and key components
3) Optimized System from a Cost, Architecture and Footprint Perspective
Newly enabled disaggregated and distributed system architecture observes the data center as a whole processing pool of resources rather than as a subset of servers, each with a dedicated function. This model distributes functions such as storage and parallel processing across multiple systems.
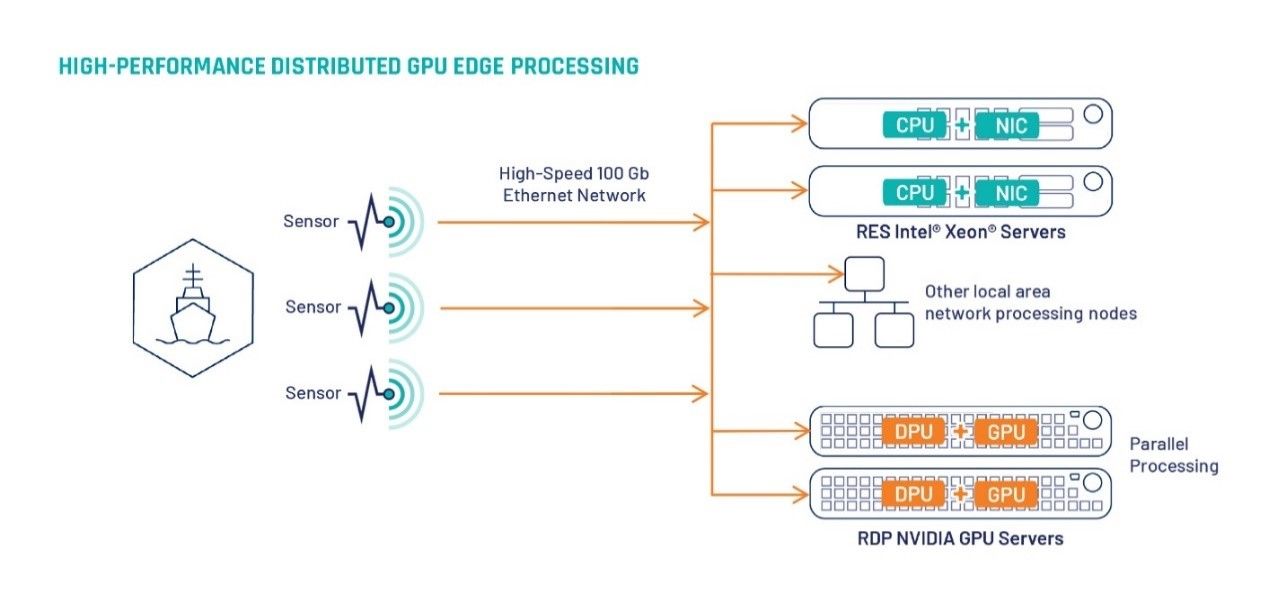
Figure 2. Use Case of Data Processing Unit in a Platform
Figure 2 shows a distributed, disaggregated sensor processing architecture. Parallel processing of mission-critical information such as sensor data is sent and performed on the GPU-enabled system, relayed to the DPU over high-speed networking, and shared to any networked server for action. Such an architecture also maintains low latency end to end, from sensor to GPU to networked server, irrespective of CPU generation in the server stack. To facilitate this new architecture, products such as Mercury’s Rugged Distributed Processing 1U server disaggregates GPU resources and distribute insights directly onto the network without a standalone x86 host CPU.
By distributing across the network, a greater portion of the resource can be used. Instead of specifying GPUs into each system and using a percentage of each GPU, fewer GPUs can be used and distributed to a greater number of systems, mitigating the trend in thermal increase. Rama Darba, Director of Solutions Architecture at NVIDIA, identified cost reduction as another key improvement from such an architecture: “One of the great advantages is that now because you’re not in a place where you know you’re locked having to run this application on this server, you could actually have huge reductions in server cost and server sizing.”
Hardware that not only enables disaggregation, but also distribution of resources, presents an opportunity to align the needs of mission-critical platforms with the latest technology through an innovative approach to architecting systems.
To learn more about distributed disaggregation processing, read this white paper and watch our short webinar (link to on-demand webinar) featuring NVIDIA’s Solutions Architect, May Casterline.




 Embrace the change
Embrace the change